機械学習の全体の流れを解説する
1.計画の立案
機械学習の目的を決め、目的に沿った手順と予測精度等をまとめて事前に資料化する。
2.データの収集
以下の点を考慮し必要なデータを可能な方法で収集する。
データの概要
データに含まれる項目、内容、期間等を把握する
データの形式
数値データが基本、なるべくテキスト化され方が扱い易い
データの作成過程
作成過程の違いによって前処理の負荷が変わってくる
入手先
入手に関しては正式な手続きで行う
入手コスト
有償データも考慮してみる
個人情報や機密情報
可能な限り収集しない
3.データの前処理
収集したデータを機械学習できるように整える。データに合わせて試行錯誤しながらプログラムを組み立てる。 既に数多くのデータ操作用にプログラムが各データ構成に対して用意されているので、取捨選択し使用する。
前処理の結果として処理済みデータ(目的変数、説明変数)が残る。
データの読み込み
「Pandas」ライブラリの「DataFrame」をよく使用する
データ操作の「Pandas」については後段の補足参照
データの確認
データの分布、偏りをグラフ等を使って確認する
欠損値の確認
データの不備を補ったりデータの誤りを修復する
データ型の変換
文字列等を数値データに変換する
説明変数の作成
必要に応じて、モデル構築に有効な説明変数に加工する
不要な説明変数は削除する
データの正規化
必要に応じて、データを一定の範囲内に収める
4.モデルの構築、学習、評価
モデル構築にはプログラムの作成が不可欠。既に数多くのプログラムが各モデルに対応して用意されているので、取捨選択し使用する。
データの分割
既存のデータを学習用に8割程度、評価用に2割程度に分割
さらに学習用データを
学習用に8割程度、学習中の検証用に2割程度に分割
モデルの選択
多くのモデルの中からデータに適したモデルを選び出す
機械学習用ライブラリの「scikit-learn」は後段の補足参照
モデルの学習、評価、調整
選択したモデルを使って、学習用データで学習する
学習済みモデルの性能を検証用データを使って評価する
最後に評価用データを使ってモデルの性能を評価する
5.導入
準備作業の一環として前工程と並行して進める。
導入形態の検討
テスト環境から本番環境への移行
ユーザインターフェース
他システムとの調整
本番環境の調査
必要なソフトの準備(インストール等)
システム統合された環境の整備
既存システムの修正
導入効果を測定するための環境整備
運用・保守の検討および実行
6.運用、モデルの改善
モデルの予測精度は徐々に悪化するのが一般的。
定期的に予測精度のモニタリングを行う
新しいデータを収集してモデルの再学習を行う
学習結果の反映を行う
<補足>
データの前処理に利用するライブラリ
 pandas | データ解析を支援するライブラリ 数表および時系列データを操作するためのデータ構造と演算を提供する 扱うデータ型式はCSV、テキストファイル、Excel、SQLデータベース 等々 |
モデルの選択時に利用するライブラリ
 scikit-learn | オープンソース機械学習ライブラリ 様々な分類、回帰、クラスタリング等のアルゴリズムを備えたライブラリ データを分析したり加工したりできる |
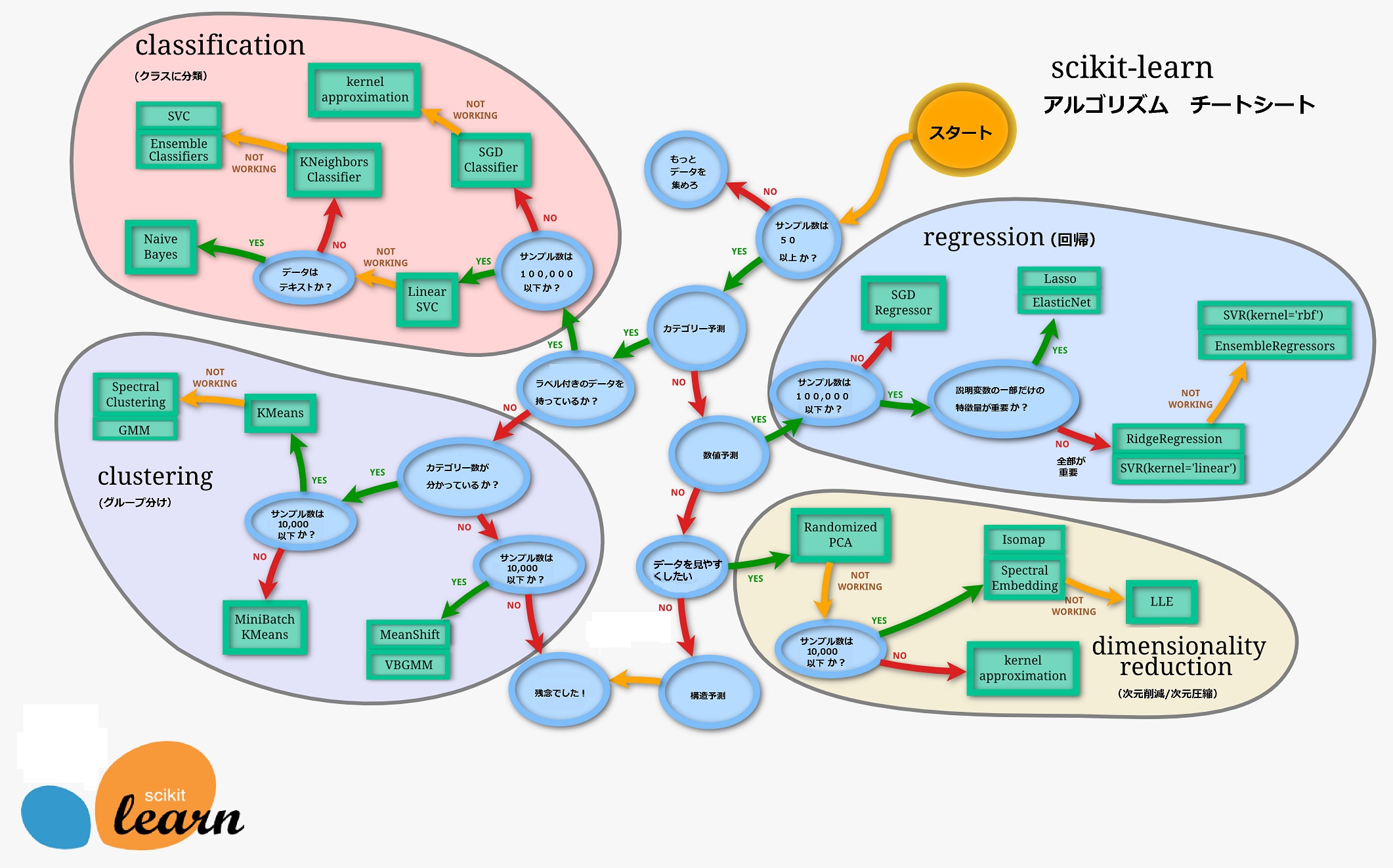 チートシート | 「チートシート(虎の巻)」の例 モデル選択の際、「虎の巻」として参考にする 数種類の「虎の巻」が既に存在する |
コメントを残す